每过一段时间就有人跳出来说微软不行了,.NET不行了,然后就去舔Java, 但是一直让我觉得比较奇怪的是,几年以后那些人还在用.NET,而且继续喷着.NET, 舔着JAVA, 在我看来,这些人和那些天天喷自己的公司,却依然在那个公司,天天喷中国,却依然在中国的那些人是一样的。
语言只是工具
因为我不是非常熟习JAVA, 所以我不知道JAVA擅长做什么,但是我觉得.NET能做的事,基本上JAVA应该都能做,就像我认为JAVA能做的事.NET基本也都能做一样。但是奇怪的是我经常看到的是.NET人员喷.NET, 很少听到JAVA人员喷.NET, 不过我估计很多JAVA人员应该也忙着去喷JAVA吧。这个其实和语言没关系,只是和人的心理有关系,因为人总觉得“碗里的没锅里的好”。
语言之争已经持续很多年了,其实这个大家都知道没什么意义,网上不是流传一个语言的鄙视链吗?我觉得大家把他当个玩笑罢了,千万别当真,因为不管怎么鄙视,我们毕竟要吃饭的。
本来我也觉得写这篇文章没什么意义,但是看到那些喷.NET文章,基本上句句说的都没理,但是却可能对初入行的人带来很大的误解,就像骗子很容易骗小孩,因为小孩涉世未深。
我做开发已经10多年了,学过很多语言,但是真正用来吃饭的最主要的语言其实是Visual Basic和.NET, 当然还有”汉语”. 当初也学过Java, JSP, SSH. 但是最后选择了.NET,为什么,一是因为.NET技术真的入门很快,当年入门快的好处之一就是你立马就有一定的生产力,也就是你能很快开始干活,这样就有公司愿意给你付薪水了,也就意味着你可以更早从父母那里断奶了,另外一个原因就是当时面试的要.NET比要JAVA的多呀。
C# 语言
我学习过C, Java,Visual Basic, Ruby,Node.js等,但是我还是觉得C#是生产力非常高的一门语言,比如一些非常优秀的语言特性,你刚刚才能从其它语言里看到一点点,比如自动属性,LINQ, Lamda表达式,Action等,另外C#对多线程的封装让我们在多线程编程时极其方便,比如TPL. 还有令大家头疼的异步回调的问题,C#用非常优雅的Async, Await来解决,我们看到ES7里面已经开始实现类似的东西,是不是借鉴了C#呢?
多语言混用
对一个稍微复杂一点的程序来说,我们为什么一定要只使用一个语言呢?比如我们前端可以使用ASP.NET MVC, 后端可以使用Java 甚至是别的任何一个语言,服务我们可以使用WCF, 搜索我们可以使用Solar等等,我们甚至是WEB层,业务层都是用.NET, 而数据库可以使用MySQL或者MongoDB.
.NET或者JAVA只是系统的一部分
我们知道一个WEB程序,除了后端以外,很多其它的东西比如HTML, CSS,JavaScript,数据库这些不管你做Java还是.NET都是一样需要的。也就是前端技术都是相同,另外HTTP协议,TCP/IP这些也不分语言吧。不管你是JAVA还是.NET, AngularJS, ReactJS, HTML5, Bootstrap, Bower, Grunt, Gulp这些东西对你都是一样的吧?
微软技术能做什么
我没有做过JAVA程序,但是我使用微软技术10多年了,我就说一说微软技术能做什么。
桌面程序
Visual Basic
当年我毕业没多久,就加入一家马来西亚在中国的软件公司,这个公司主要是做门票系统,当时我们选择了Visual Basic, 做过VB的人都知道VB是多么的强大,除了极其方便的可见即所得的Form外,而且有几乎一切你想要的组件,另外我们都知道Windows是桌面系统中当之无愧的的霸主, 我不知道JAVA在这方面的优势是什么,如果有些人说要跨平台,但是我做了这么多年的企业软件,没有几个企业软件是需要跨平台的。当时在这个公司里做了售票系统,还有闸机系统,POS系统,我估计很多人不知道闸机系统原来用Visual Basic也可以做。广州,北京最大的游乐园都是我们当年做的,而当年整个乐园的信息系统都是使用的微软的技术。
WPF
微软推出的WPF, 我觉得是对桌面开发程序的极大的进步,几乎所有的桌面程序的展示都可以使用WPF来呈现,而通过WPF可以让我们非常方便快速的做出非常炫的桌面程序,WPF的XAML方式给了我们非常方便的写桌面窗体。 同时模板,动画等在WPF都是极其容易实现,另外MVVM在WPF的应用里非常盛行,WPF可是比Angular早出现了很多年。
UWP
不久前,微软推出了Windows 10, 这使一套系统可以运行在桌面,平板以及手机上,而我们可以使用XAML,甚至是JavaScript来开发一套程序就可以运行在多个终端,这个对个人用户可能没有什么,但是对企业用户太重要了,具体的细节我觉得大家可以去看一下MSDN或者Channel9
WEB
我觉得很多人对微软的误解可能主要是这一部分,当年的ASP.NET WEB Forms由于是快速拖控件,导致界面生成很多难以认识的代码,大量的ViewState等,但是这并不能说ASP.NET WEB Forms不好,第一我们可以使用ASP.NET WEB Forms快速完成一些小型的WEB程序,加上有大量的第三方控件,是开发一些常规的程序快如闪电。第二我们可以尽量使用客户端的控件比如Repeater等,现在仍然有很多网站都是ASP.NET WEB Forms做的,难道这些网站都没有用户?!
ASP.NET WEB MVC
由于很多人对ASP.NET WEB Forms充满抱怨,而且WEB开发技术不断地革新,微软也顺应潮流及时的推出了ASP.NET MVC, 使用MVC可以写出非常清爽的代码,我们团队从ASP.NET MVC1.0 beta就开始使用,由于我也学习过Ruby On Rails,基本上这两个框架非常相似,极其方便的路由管理,View, Controller, Model的分层,使我们可以很好的使用强类型类开发,我们已经使用ASP.NET MVC成果提交过很多项目,还从来没有遇到过问题是出自.NET本身的。
WEB 服务
WCF
使用统一的模型,让我们开发WEB服务极其方便,大部分情况下我们只需要定义一个接口,配置相关的Binding和EndPoint就可以了,可以很方便的使用Http, TCP, Https,可以非常方便的使用各种安全策略,而这些就只需要简简单单的几行配置而已,WCF极大的简化了WEB服务的开发。
ASP.NET WEB API
除了WCF, 微软又推出了ASP.NET WEB API, 使得我们开发轻量级的WEB 服务极其容易,使用ASP.NET WEB API 我们可以非常容易实现服务的Restful. 而使用OWEN我们可以以任何方式来部署我们的API。
Azure 微软云
微软的云非常的强大,使用过微软云的都知道,微软云几乎可以满足我们一切对程序的要求,我们可以使用Azure web apps很方便的创建一个WEB, Webjob, 我们可以使用Azure SQL, 使用Azure storage, 可以极其方便的使用云的Queue, Bus等等,而且云集成了很多优秀的第三方程序,比如我们可以使用Redis作为Cache. 另外微软的Cloud Services让我们可以极其方便的管理我们的部署。这让我们很多程序员从一个程序员可以快速成为可以运维企业整套系统的人,而你只需要学习一些Azure的管理知识,比如自动扩展等等,而这些在云里面都可以快速简单的配置。我们几乎一半客户的系统都运行在Azure里面,而且我们可以一键部署,如果有问题,我们甚至可以使用Visual Studio来直接Debug云里面的网站。
移动开发
由于Mono,现在可以使用.NET来开发移动的应用程序,使用Xamarin可以使用C#开发出和原生性能一模一样的iOS和Android程序,我也熟悉Objective-C, 而且用Objective-C开发过程序,虽然说Objective-C 在某些方面很优秀,但是开发效率实在不敢恭维,不然Apple也不会推出Swift来革自己的命,另外当你既需要iOS,又需要Android的时候,你至少需要一个熟悉Objective-C的,又需要一个熟悉Java. 而同样地东西需要做两遍。而使用Xamarin做企业级APP,大量的业务逻辑可以共享,更别说可以直接使用效率非常的C#语言了,我们已经成功提交了好几个基于Xamarin的程序。
另外,Xamarin推出的Xamarin.Forms可以使用XAML及C#用一套代码来开发iOS, Android以及Windows Phone的程序,而且性能和原生的一模一样,我们也顺利开发过基于Xamarin.Forms的程序。
游戏开发
现在已经有很多程序基于Unity开发,而你可以选择C#来作为基于Unity的游戏的主要语言。可以搜索一下,已经有大量的上架游戏是使用.NET开发的。
小结
当然,以上只是我使用的微软相关技术,目前来说,除了客户明确选择其它语言以外,还真的没有多少是Java能做而.NET做不了的。
桌面,WEB, 移动开发 都可以使用.NET,简单点说,就是你都可以使用一门语言,那就是C#来开发
开发工具
Visual Studio
做.NET开发,配套的开发工具是Visual Studio, 我觉得Visual Studio是最好的IDE之一,你几乎可以使用做任何语言的开发,这个使用过的人都非常清楚,虽然说Vim是编辑器之神,而Emacs是神的编辑器,但是显示世界能有多少个神?
Resharper
Resharper是每个.NET程序员的必备工具之一,基本上可以让我们的开发效率提高三分之一,设个谁用过谁知道。
领域驱动设计
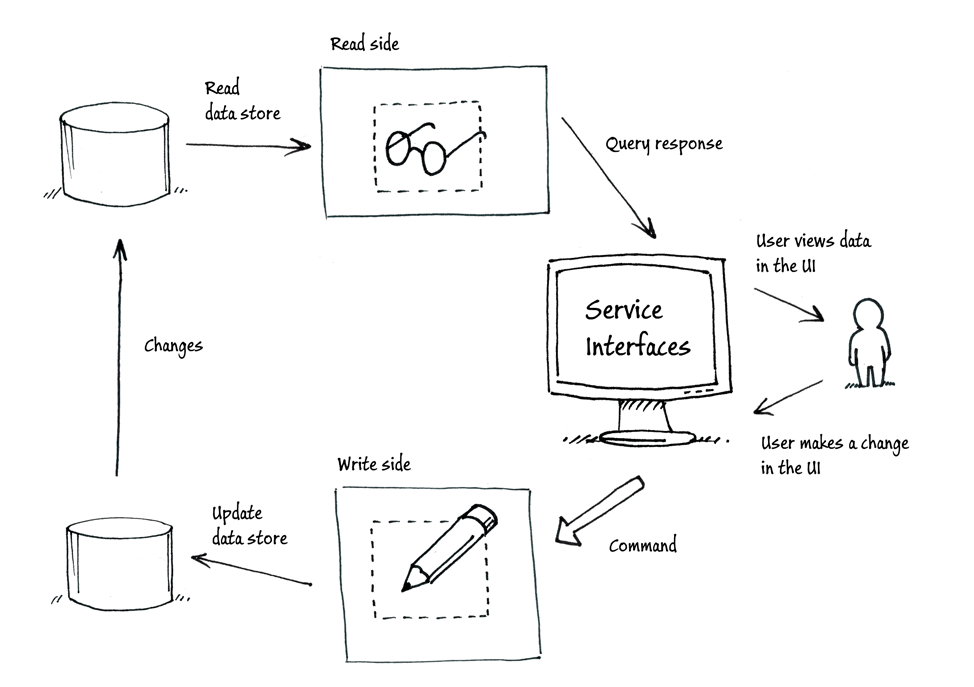
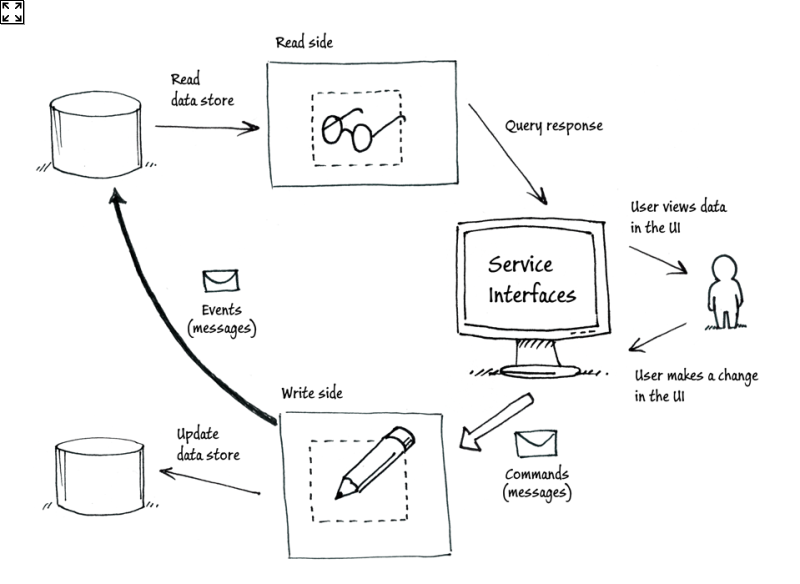
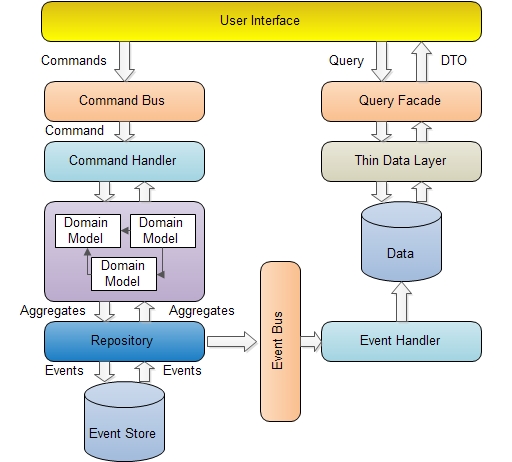
如果我没有记错的话,虽然Eric Evans较早写了领域驱动设计一书,但真正推动领域驱动设计的是有很多做.NET开发的,比如Greg Young, 我们可以看看NServicebus. 可以看看 NServicebus
我们已经使用领域驱动设计提交了一个非常大型的项目,这个项目是一个世界500强的主要系统。而这个系统就是使用的.NET C#,使用了CQRS, NServicebus, ASP.NET MVC, ASP.NET WEB API,SQL Server等等,系统已经运行了好几年了,还没有发现什么问题。
有兴趣的可以关注一下我的领域驱动系列。
长尾理论
很多人说大型的一些系统都没有用.NET, 比如BAT, 比如新浪微博,他们是不是一点都没有用.NET我不知道。我想说的第一那些系统都比较庞大,使用JAVA或者PHP很多时候是基于历史的选择,另外这些系统就那么几个,而且并不是所有的软件都是电商,都是微博?
我在这里想说的长尾,就是第一中小企业几乎占据所有的企业的80%, 而这些企业需要各种各样的系统,而这些企业不论是国内还是国外,都是Windows占大部分。虽然我也非常喜欢苹果的产品,但是企业是需要赚钱的。 也就是说80%的企业都不会像BAT那么大,那么至少这80%的系统使用.NET开发没有任何问题,再加上.NET有着很高的开发效率,我们有什么理由不选择呢?
使用.NET应该是企业或者客户项目的第一选择
如果只做WEB系统,或者只做电商之类,那么使用其它任何语言都没问题,但是一旦做企业系统,往往.NET是一开始非常安全的选择,为什么? 因为很多企业使用的系统是Windows, 使用的办公软件是Office, 使用的服务器是Windows Server,使用的是AD, 使用的邮件系统是Exchang Server, 我不知道你们使用JAVA和PHP和这些系统集成时是否方便,但是使用.NET是非常方便的。目前来看,.NET几乎可以满足企业应用的所有的现有的需求以及潜在的需求。
关于开源,关于免费
现在.NET很多东西都开源了,.NET CORE 和 ASP.NET VNext已经可以跑在Mac和Linux上了,我相信会越来越多的.NET程序将来会跑在Linux服务器上,另外大部分程序根本就用不了那么多服务器,如果我们真的需要那么多服务,证明公司已经很有钱了,还买不起几个Windows?而且如果真的需要那么多服务器,我们可以使用Microsoft Azure, 买几个Windows总比要请几个Linux运维工程师要便宜很多吧。
最后,没有人限制你只会.NET
没有谁能限制.NET程序员学习其他的语言,.NET程序员可以学习Java, Ruby, Node.js, 可以学习Event Driven, Message Queue, Solar, 学习MongoDB, Redis, 学习分布式缓存,学习任何其它语言需要学习的东西。
关于薪水
我不相信一个人学两个月JAVA, 不学习其它东西就可以立马成为一个优秀的程序员,就可以拿到很高的薪水,因为在我看来,要成为一个优秀的.NET程序员,需要学习大量的知识,我相信JAVA程序员也是一样。如果说.NET程序员年薪几百万我没见过,但是把.NET学好可以拿到相对不错的薪水还是没有问题的。
我们就是使用.NET的技术,如果你觉得你.NET技术还可以而没有地方发挥的,欢迎联系我 wangdeshui@outlook.com









 这个我们在前面介绍公钥密码体制时介绍过,公钥是用来对消息进行加密的。
这个我们在前面介绍公钥密码体制时介绍过,公钥是用来对消息进行加密的。